Of Squids and Squirrels
We've discussed many captivating topics, ranging from distributional substitutability to topological similarity and neural networks. But here's the one topic you really wanted to hear about: squid vs. squirrel.

Blankcrack is an online game I coded for my dissertation. It's available in English, French, Italian, Spanish and Russian. The whole point of this game is to put humans in a situation comparable to how we train word embeddings.
The whole pitch of the game was to have people guess which of two words match a series of fill-in-the-blank sentences. The interface looks basically like that:

Here, you have five sentences, and two words to chose from: the whole point of the game is to have you guess which one of these two words fits in all five of the blanks. To create these blank sentences, what we do is that we start from a pair of words we have some reason to think could be substitutable (say "jump" and "climb"), then we select up to five sentences where one of the two words occur and the other word does not. And we simply replace the word that systematically occurs with a blank space. We now have a set of contexts we can show to users, along with a correct answer (only one of these words actually corresponds to the sentences). If players select the correct word at chance level, then we can say that these two words are indeed substitutable.
We've already covered why this is comparable with how word embedding models, (from which we derive word vectors) are trained in the previous post, but here's a short recap anyways: most word embeddings models are trained to solve fill-in-the-blanks types of tasks. Not all models are equally easy to convertc to this fill-in-the-blanks sort of setup, but the most famous and recent ones can all be converted to that setup. However, models are trained on many sentences at once, not just one; which is why in this game we present multiple sentences to humans.
As for why this game is themed with squids and squirrels: there's absolutely no reason. I just ended up using some of my doodles that were good enough, and wrote a couple of silly puns to go along with it.
So we have a game designed to collect human judgments on distributional substitutability that we can compare to what our embedding models suggest. Let's jump right in! The most basic thing we can compare is the number of times the correct word we actually attest is selected. Let's look at all five languages, and let's compare the performances of word2vec, BERT, as well as unigrams (i.e., the strategy of picking the most frequent of the two words: we'll always chose "potato" over "superciliousness") and bigrams (i.e., the strategy of pikcing the most frequent of the two words given the word that immediately precedes it: if we have the word "an" before a blank, then we'll always pick "elephant" rather than "potato", because "an elephant" occurs more often then "an potato"). These unigrams and bigram strategies are rather crude: we expect them to be baselines, and a more elaborate model like BERT or word2vec should in theory fare better. Here's what this looks like:
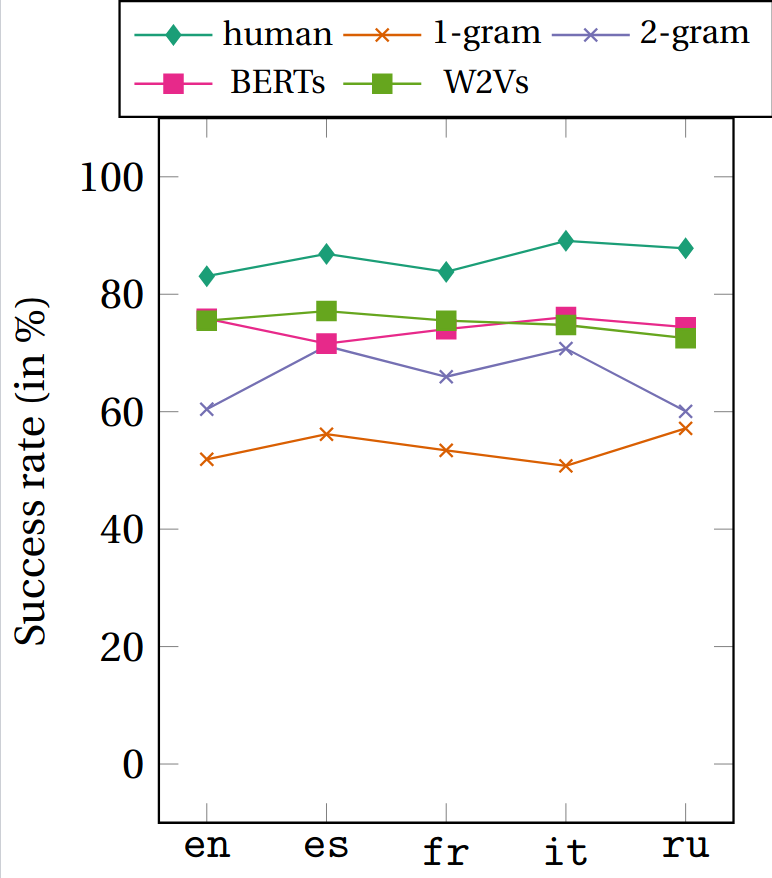
Here, the y-axis corresponds to the proportion of examples that were gotten right, so ideally we'd want this to reach 100%. What we see is that humans make mistake, but they make fewer mistakes than embedding models, whcih in turn make fewer mistakes than unigrams and bigrams.
So far so good. Let's try to be a bit more specific about what happens: are models making the same kind of mistakes than humans? Do they find the same sort of word pairs challenging? What we can do is compare how uncertain humans are when selecting a word to how narrow is the models' preference for the word they select. If humans and models find the same examples challenging, then we should expect a positive correlation. Here's what the data look like:
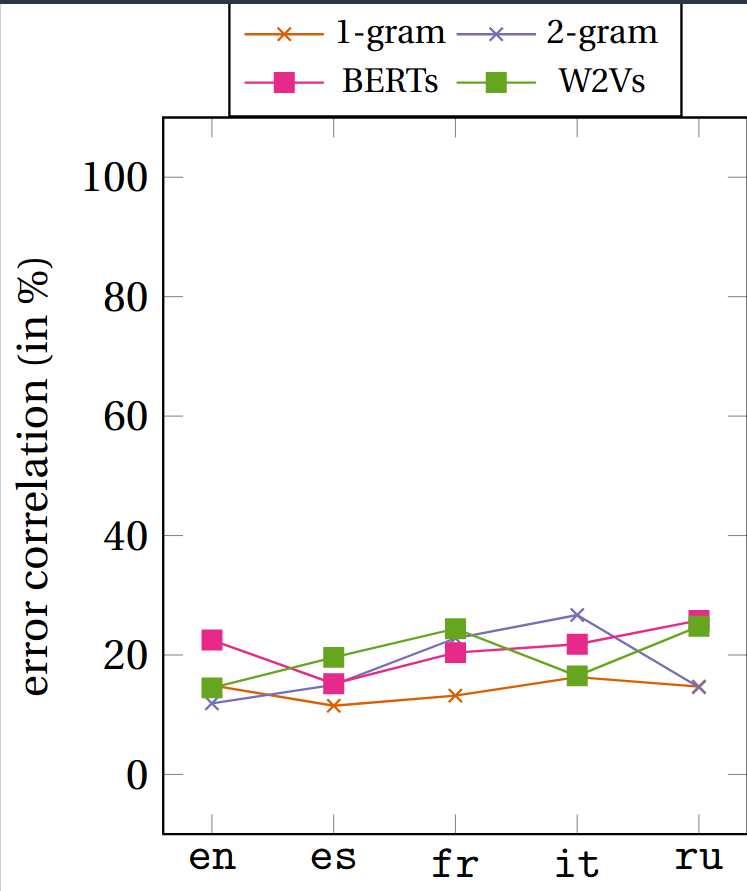
There's two things to highlight. First, we always find a positive correlation. Sure, it's not 100%, but we do see that there's some sort of relation between what humans find challenging and what models find challenging. Rather than a correlation of 100%, a more reasonable estimate would be to compare two groups of humans who have been presented the same data: in such a scenario, we'd get a correlation slightly above 40%. That's quite higher than what we see here.
The second point to factor in is that we don't really see a neat separation between sophisticated embedding models (word2vec and BERT) and baseline strategies (unigrams and bigrams). This differs from what we saw when we just compared how often the different models would select the correct word. This suggests that our models are not as good as we'd like them to be.
To sum up, comparing humans and word embedding models on fill-in-the-blanks tasks suggests that there's still a very clear divide between what these models can do and the theoretical expectations we have for them. There's room to grow, at least from the linguist's point of view. We have yet to come up with a model of human language that accurately represents what humans actually do.